We can't find the internet
Attempting to reconnect
Something went wrong!
Hang in there while we get back on track
v1 release of Rom-to-the-Com
2024-08-04 ・ side-project, machine-learning, large-language-models, rom-to-the-com
A few years ago, some friends and I went on a road-trip to Wales. How we came up with the idea has long been forgotten, but the idea lived on. I bough the domains immediately after that trip, and held onto them until now!
What’s different from now is that LLMs have hit it off, and solved the data problem for this side-project.
Before reading on, check it out: Rom-to-the-Com. Here’s a screenshot:
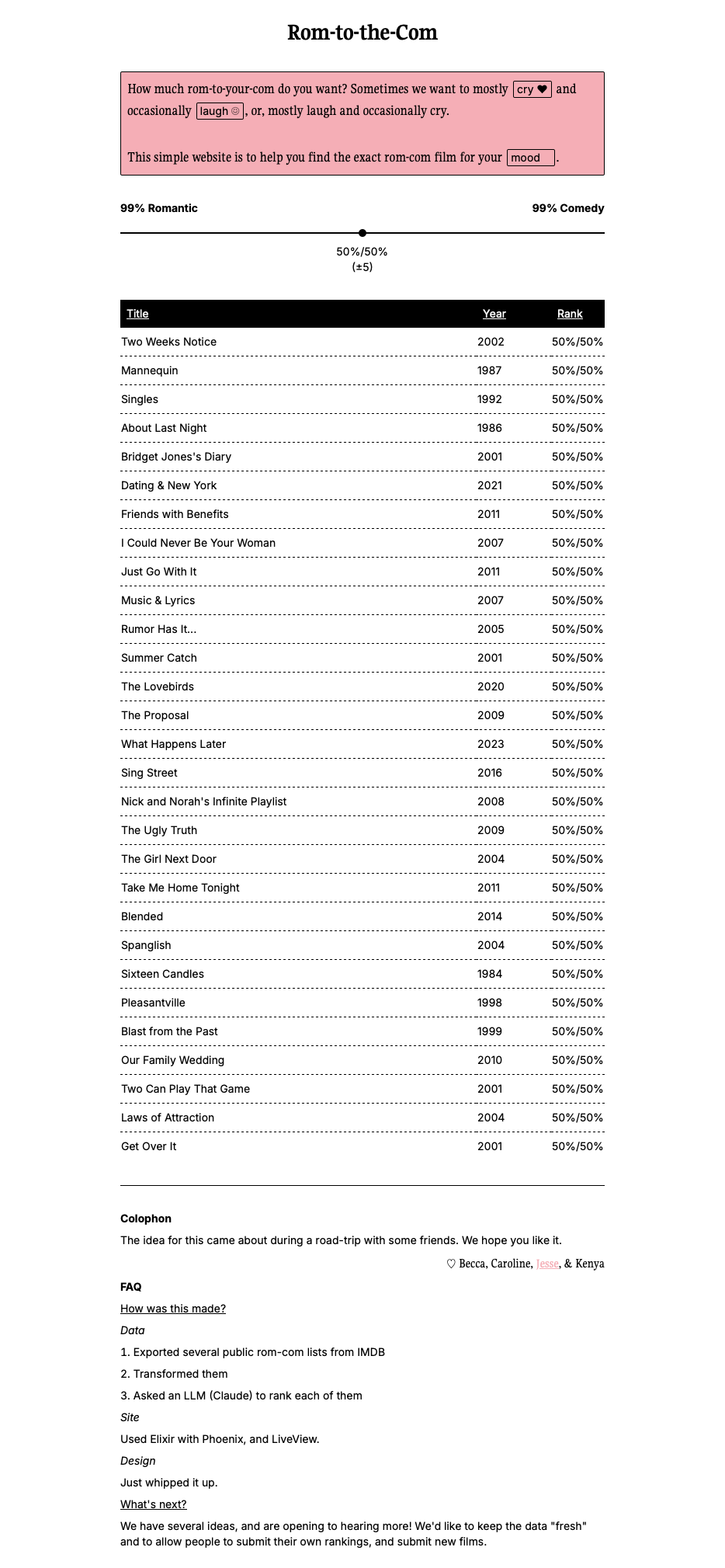
There were 2 parts to the data problem. The first is simply a list of rom-coms. There were different lists available on the internet. Wikipedia had quite a huge one. In the end, I used several public lists that people had made on IMDB. The second is how to rank them as a percentage of romance to comedy, in a timely fashion. We could do films we know, but that would be a small dataset. In the end, I used Claude, with this prompt:
message = await client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=4096,
temperature=0,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": f"For each of these romantic comedy films, determine, out of 100%, how much of them are romance and how much are comedy. For example, a film may be 60% romance and 40% comedy.\n\nReturn your determined value as a third column in the CSV text. A value should be in the format of \"60,40\", for the 2 percentages. Make sure they're surrounded by quotes, so it's a valid CSV file. Try and spread out your assessments so that there's a wide variation. Only return the result.\n\n{chunk}",
}
],
}
],
)
A chunk was n film titles. I ran a validation after, to ensure that all percentages added up to 100%, and they were all correct! I did some manual validation on the accuracy by comparing the generated rankings, to films I’ve seen. I had some friends do the same. Overall, we were quite happy with the rankings. An assumption I’ve operated on is that in the LLM’s training data, every film was present.
For the design, I kept it as minimal, and minimally cutesy, as possible.
We have lots of ideas, but for now, v1 is there!