We can't find the internet
Attempting to reconnect
Something went wrong!
Hang in there while we get back on track
Fine-tuning an LLM on my messages (WhatsApp, Instagram, and Messenger)
2024-06-25 ・ large-language-models, prototype, side-project, retrospective
This will be a brief overview of how I attempted to fine-tune an LLM on my personal messages. The goal was to 1) go through the data preparation, experimentation, and evaluation loop end-to-end, and 2) be able to side-by-side evaluate my responses to responses from the LLM. This was out of curiosity and also to practice some data and ML engineering! I’m in the process of transitioning professionally from software engineer to eventually something ML engineer-esque.
From those 2 goals, I’m happy with the first (I did it), and unsurprised by the second (the evaluations were relatively poor). Due to privacy, and time constraints, this post will be brief in length and in content of my messages and responses.
Data
Gathering
Messages from WhatsApp, Instagram, and Messenger were used. For WhatsApp, I used iMazing to get an export, as there wasn’t a first-party way for me to immediately do so. For the latter 2, I exported data from my Meta account.
Preparing
In prepare.py (see: appendix), I read in all the conversations from the different sources, and then dump them in a ChatML structure, per conversation, to disk. This structure was chosen to match the LLM I was going to fine-tune on. You can see an unused to_prompt function, for a different structure, for a different model that I was tried.
The CLI allowed me to focus on specific sources and to safely experiment with dry runs. Even for a little script, I did still appreciate having done this.
Fortunately I could use the same parsing for Instagram and Messenger. There is some data validation done during transformation to my conversation structure and post-transformation. These validations were learnt through examining the data and through seeing bad output when writing this script. These were both for conversations to exclude (e.g. no. of participants) or messages to exclude (e.g. someone leaving a group).
For myself, I decided to treat myself as the assistant, that would be queried in the evaluations. Everyone else became the user.
NB: It’s amusing seeing myself write this with some FP-first approach, compared to what I’ve seen from data scientist, and even other software engineer, colleagues.
Training
This was a struggle due to wanting to spend little time and knowing little! There are many tutorials that people have written on how to fine-tune an LLM, and there’s packages, like Unsloth and Axolotl, that make it easy (or in my case, easier, but still tricky).
After trying to get a sufficient understanding, I settled on using Modal for running the training and some inference requests, and can genuinely recommend it. My stopped “Apps” have long been lost due to I presume the plan (Starter) I’m on. The training script was based on a Modal example, using Axolotl. I used Weights & Biases for training metrics and pulled the base model from Hugging Face.
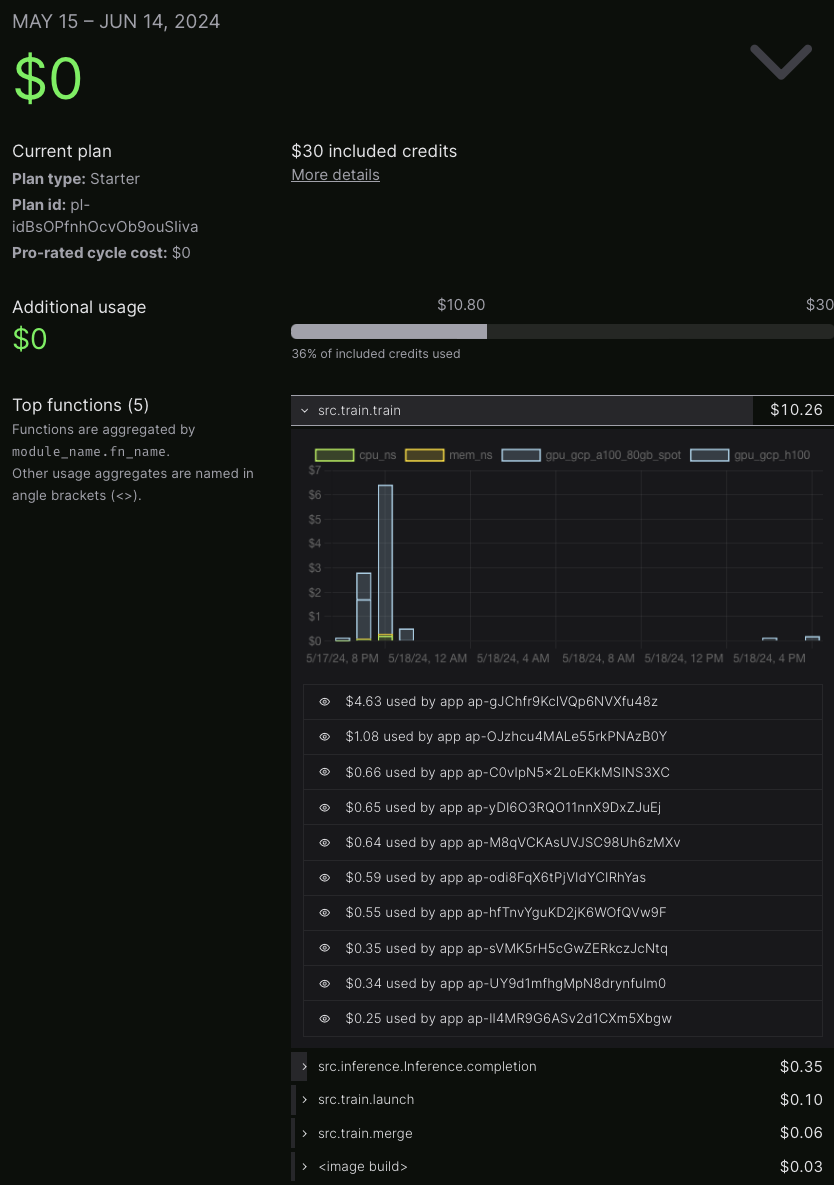
In the end, it cost me nothing, as my small usage was covered by the included $30 compute credits. The appendix contains a breakdown of the costs.
The model I had the most success with was mistralai/Mistral-7B-Instruct-v0.2. I say “most success” since I was fairly naïvely trying the right Modal config and fine-tuning parameters and settings!
Unfortunately I don’t have my logs for how long it took, but it was relatively quick, on the GPUs I used through Modal. That’s really not helpful, so hopefully I’ll reproduce the process.
Evaluation
I had 2 baselines of 1) 0-shot prompt and 2) 0-shot prompt but with a summary of who I (that is, the assistant) am. The latter was interesting in an existential sense to see how common/present my kind of life was present in the model.
For some messages from friends or colleagues, I’d write my own response, and then get the 2 responses from the baselines. Again, I used Modal for serverless inference.
The responses were fairly generic. There did seem to be recall of things specific to my life, as presented through messages though. My writing style didn’t seem to come across explicitly. Mostly, my style of humour with my friends didn’t either.
Outside of messages, I did ask questions like “where have I been on holiday”, and the responses were just slightly better than a baselines, but not enough to be meaningful.
Appendix
prepare.py
import argparse
import csv
import io
import json
import os
import re
import uuid
from dataclasses import dataclass
from datetime import datetime
from enum import Enum
from functools import reduce
from pathlib import Path
from typing import Any, Generic, List, TypeVar, Union
import structlog
from dataclass_wizard import JSONFileWizard
class Role(Enum):
SYSTEM = "system"
USER = "user"
ASSISTANT = "assistant"
im = "<|im_start|>{role}\n{content}<|im_end|>"
system = "You are ..."
log = structlog.get_logger()
whoami = "Jesse ..."
data_file_path = Path("data.jsonl")
def get_percentage(part, whole):
if whole == 0:
return 0
return round((part / whole) * 100, 2)
class Source(Enum):
MESSENGER = "Messenger"
INSTAGRAM = "Instagram"
WHATSAPP = "WhatsApp"
T = TypeVar("T")
E = TypeVar("E")
@dataclass
class Ok(Generic[T]):
value: T
def __str__(self):
return f"Ok({self.value})"
@dataclass
class Err(Generic[E]):
error: E
def __str__(self):
return f"Err({self.error})"
Result = Union[Ok[T], Err[E]]
def unwrap(result: Result) -> T:
match result:
case Ok(value):
return value
case Err(err):
raise ValueError(f"can't unwrap: {err}")
def is_ok(result: Result) -> bool:
match result:
case Ok(_):
return True
case Err(_):
return False
def is_err(result):
match result:
case Ok(_):
return False
case Err(_):
return True
@dataclass
class Message(JSONFileWizard):
id: uuid.UUID
participant_id: uuid.UUID
timestamp: str
content: str
role: Role
@dataclass
class Participant(JSONFileWizard):
id: uuid.UUID
name: str
@dataclass
class Conversation(JSONFileWizard):
id: uuid.UUID
messages: List[Message]
participants: List[Participant]
source: Source
path: Path
def is_group_conversation(self) -> bool:
# Assuming a group conversation has more than two participants
return len(self.participants) > 2
def to_prompt(self) -> str:
def proc(acc, message):
role: str = message.role.value
if message.role == Role.USER:
for participant in self.participants:
if participant.id == message.participant_id:
role = participant.name
break
return (
acc
+ "\n"
+ im.format(
role=role,
content=message.content,
)
)
return reduce(
proc,
self.messages,
im.format(role=Role.SYSTEM.value, content=system),
)
# https://openaccess-ai-collective.github.io/axolotl/docs/dataset-formats/conversation.html#sharegpt
# optional: first row with role system to override default system prompts
# {"conversations": [{"from": "...", "value": "..."}]}
# from: human
# from: assistant
def to_chatml(self) -> Result[str, str]:
conversations = []
message = self.messages[0]
prev_role = message.role.value
prev_content = message.content
for message in self.messages[1:]:
next_role = message.role.value
next_content = message.content
if next_content == "":
# log.debug("skipping empty message")
continue
if prev_role != next_role:
# log.debug("different roles", prev_role=prev_role, next_role=next_role)
if prev_content != "":
conversations.append(
{
"from": prev_role,
"value": prev_content,
}
)
prev_role = next_role
prev_content = next_content
else:
# log.debug("same roles", prev_role=prev_role, next_role=next_role)
prev_content += "\n" + next_content
# After possibly combining messages, check the length
if len(conversations) < 2:
return Err("too few messages")
data = {"conversations": conversations}
return Ok(json.dumps(data))
class FacebookIO(io.FileIO):
def read(self, size: int = -1) -> bytes:
data: bytes = super(FacebookIO, self).readall()
new_data: bytes = b""
i: int = 0
while i < len(data):
if data[i:].startswith(b"\\u00"):
u: int = 0
new_char: bytes = b""
while data[i + u :].startswith(b"\\u00"):
hex = int(bytes([data[i + u + 4], data[i + u + 5]]), 16)
new_char = b"".join([new_char, bytes([hex])])
u += 6
char: str = new_char.decode("utf-8")
new_chars: bytes = bytes(json.dumps(char).strip('"'), "ascii")
new_data += new_chars
i += u
else:
new_data = b"".join([new_data, bytes([data[i]])])
i += 1
return new_data
def parse_conversation_messenger_instagram(
file_path: str, source: Source
) -> Result[Conversation, str]:
f = FacebookIO(file_path, "r")
data = json.load(f)
# with open(file_path, "r") as file:
# data = json.load(file)
participants = list(
map(
lambda participant_data: Participant(
id=uuid.uuid4(), name=participant_data["name"]
),
data["participants"],
)
)
if len(participants) < 2:
# log.warn("insufficient participants", count=len(participants))
return Err("insufficient participants")
# Use my full name, for consistency
if source == Source.INSTAGRAM:
idx = None
for i, participant in enumerate(participants):
if participant.name == "Jesse":
idx = i
break
participants[idx].name = whoami
messages = []
for message_data in data["messages"]:
content = message_data.get("content")
if content is None or content == "":
continue
for ignore in [
r".*left the group\.$",
r".*added.*as a group admin\.$",
r".*added.*to the group\.$",
r".*named the group.*",
r".*sent an attachment\.$",
r"^You are now connected on Messenger\.$",
r".* sent a live location\.$",
]:
if re.match(ignore, content):
# log.debug("skipping message", pattern=ignore, content=content)
continue
sender_name = message_data["sender_name"]
if source == Source.INSTAGRAM and sender_name == "Jesse":
sender_name = whoami
participant_id = next(
(p.id for p in participants if p.name == sender_name), None
)
if participant_id is None:
# They're no longer in the group. One reason for that is them leaving.
# log.debug("missing participant", sender_name=sender_name)
participant = Participant(
id=uuid.uuid4(),
name=sender_name,
)
participants.append(participant)
participant_id = participant
if sender_name == whoami:
role = Role.ASSISTANT
else:
role = Role.USER
if message_data.get("content") is None:
# log.debug("missing content", has_photos="photos" in message_data)
continue
message = Message(
id=uuid.uuid4(),
participant_id=participant_id,
timestamp=datetime.fromtimestamp(
message_data["timestamp_ms"] / 1000
).isoformat(),
content=content,
role=role,
)
messages.append(message)
conversation = Conversation(
id=uuid.uuid4(),
messages=messages,
participants=participants,
source=source,
path=file_path,
)
return Ok(conversation)
# TODO If phone number in file name, generate names
def parse_conversation_whatsapp(file_path) -> Result[Conversation, str]:
participants = []
messages = []
with open(file_path, "r") as file:
reader = csv.DictReader(file)
for row in reader:
if row["Type"] not in ["Outgoing", "Incoming"]:
# log.debug("ignorable type", type=row["Type"])
continue
sender_name: str = row["Sender Name"]
if row["Type"] == "Outgoing":
sender_name = whoami
participant_id = next(
(p.id for p in participants if p.name == sender_name), None
)
# We haven't seen this participant before
if participant_id is None:
participants.append(
Participant(
id=uuid.uuid4(),
name=sender_name,
)
)
if row["Type"] == "Outgoing":
role = Role.ASSISTANT
elif row["Type"] == "Incoming":
role = Role.USER
if row["Text"] == "":
continue
message = Message(
id=uuid.uuid4(),
participant_id=participant_id,
timestamp=datetime.strptime(
row["Message Date"],
"%Y-%m-%d %H:%M:%S",
).isoformat(),
content=row["Text"],
role=role,
)
messages.append(message)
conversation = Conversation(
id=uuid.uuid4(),
messages=messages,
participants=participants,
source=Source.WHATSAPP,
path=file_path,
)
return Ok(conversation)
def post_validate(result: Result[Conversation, str]) -> Result[Conversation, str]:
match result:
case Ok(conversation):
if len(conversation.participants) < 2:
return Err("too few participants")
if len(conversation.messages) < 2:
return Err("too few messages")
return Ok(conversation)
case Err(_):
return result
def dump(conversations: List[Result[Conversation, str]], dry_run: bool) -> Any:
for conversation in conversations:
conversation = unwrap(conversation)
if dry_run:
continue
# path = Path("conversations") / (str(conversation.id) + ".json")
# with open(path, "w") as file:
# conversation.to_json_file(path)
# path = Path("prompts") / (str(conversation.id) + ".txt")
# with open(path, "w") as file:
# prompt = conversation.to_prompt()
# file.write(prompt)
with open(data_file_path, "a+") as file:
chatml = conversation.to_chatml()
match chatml:
case Ok(data):
file.write(data + "\n")
return None
case Err(_):
return None
if __name__ == "__main__":
# Example: Single file
# path = Path(
# "data/facebook-messenger/..._10155675193056425/message_1.json"
# )
# conversation = parse_conversation_messenger_instagram(path, Source.MESSENGER)
# conversation = post_validate(conversation)
# log.info(conversation)
parser = argparse.ArgumentParser()
parser.add_argument("--whatsapp", action="store_true")
parser.add_argument("--instagram", action="store_true")
parser.add_argument("--messenger", action="store_true")
parser.add_argument("--dry-run", action="store_true")
args = parser.parse_args()
parse_whatsapp = args.whatsapp
parse_instagram = args.instagram
parse_messenger = args.messenger
dry_run = args.dry_run
if not dry_run and os.path.exists(data_file_path):
os.remove(data_file_path)
if parse_whatsapp:
log.info("parsing", source=Source.WHATSAPP.value)
base = Path("data/whatsapp")
files = [entry.name for entry in base.iterdir() if entry.is_file()]
success = []
fail = []
for path in files:
path = base / path
# log.info("parsing", path=path)
conversation = parse_conversation_whatsapp(path)
conversation = post_validate(conversation)
# log.info("parsed", path=path, success=is_ok(conversation))
if is_ok(conversation):
success.append(conversation)
if is_err(conversation):
fail.append(conversation)
log.info(
"parsed",
source=Source.WHATSAPP.value,
success=len(success),
fail=len(fail),
total=f"%{get_percentage(len(success), len(fail) + len(success))}",
)
log.info("dumping", source=Source.WHATSAPP.value)
dump(conversations=success, dry_run=dry_run)
log.info("dumped", source=Source.WHATSAPP.value)
if parse_instagram:
log.info("parsing", source=Source.INSTAGRAM.value)
base = Path("data/instagram-messages")
dirs = [entry.name for entry in base.iterdir() if entry.is_dir()]
success = []
fail = []
for dir in dirs:
path = base / dir / "message_1.json"
# log.info("parsing", path=path)
conversation = parse_conversation_messenger_instagram(
path, Source.INSTAGRAM
)
conversation = post_validate(conversation)
# log.info("parsed", path=path, success=is_ok(conversation))
if is_ok(conversation):
success.append(conversation)
if is_err(conversation):
fail.append(conversation)
log.info(
"parsed",
source=Source.INSTAGRAM.value,
success=len(success),
fail=len(fail),
total=f"%{get_percentage(len(success), len(fail) + len(success))}",
)
log.info("dumping", source=Source.INSTAGRAM.value)
dump(conversations=success, dry_run=dry_run)
log.info("dumped", source=Source.INSTAGRAM.value)
if parse_messenger:
log.info("parsing", source=Source.MESSENGER.value)
base = Path("data/facebook-messenger")
dirs = [entry.name for entry in base.iterdir() if entry.is_dir()]
success = []
fail = []
for dir in dirs:
path = base / dir / "message_1.json"
# log.info("parsing", path=path)
conversation = parse_conversation_messenger_instagram(
path, Source.MESSENGER
)
conversation = post_validate(conversation)
# log.info("parsing", path=path)
if is_ok(conversation):
success.append(conversation)
if is_err(conversation):
fail.append(conversation)
log.info(
"parsed",
source=Source.MESSENGER.value,
success=len(success),
fail=len(fail),
total=f"%{get_percentage(len(success), len(fail) + len(success))}",
)
log.info("dumping", source=Source.MESSENGER.value)
dump(conversations=success, dry_run=dry_run)
log.info("dumped", source=Source.MESSENGER.value)
Modal compute costs