We can't find the internet
Attempting to reconnect
Something went wrong!
Hang in there while we get back on track
First shell command prediction model
2025-11-19 ・ machine-learning, side-project, pytorch, shell
Idea
There are several daily activities you do as an X engineer in your terminal. For example, I err on the side of regularly keeping my Git repositories in sync, with regular rebasing—and restacking, with stacked changes. These are minor things, but they add up as some niceties of computing.
To take agents to a proactive, instead of reactive, stance, why not have something do things for me without being asked?
On this, I’ve been thinking of how I could predict shell commands, over 3 dimensions:
- The command itself
- When the command run
- Which command to run after a previous command
I’ve started experimenting with some of the dimensions, in particular the first.
First architecture
An LSTM was the first architecture I’ve decided to try. A few possible reasons it’s a good fit:
Diagram
- Sequential dependencies of tokens in a shell command could be a good fit
- Long-range context, to remember things such as piped commands dependencies
- Variable length of commands from a token (
ls) to long ones
class ShellNext(nn.Module):
"""
Predict the next word in a shell command.
Input
→ Embedding
→ LSTM
→ Linear
→ Softmax
- Small vocabulary
- Clear word boundaries
"""
def __init__(
self,
vocab_size: int,
embedding_dim: int,
hidden_dim: int,
num_layers: int,
dropout: float,
):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(
input_size=embedding_dim,
hidden_size=hidden_dim,
num_layers=num_layers,
batch_first=True,
# Dropout in LSTM is for between LSTM layers,
# so it's not needed if there's ≤ 1 layer
dropout=dropout if num_layers > 1 else 0,
)
self.dropout = nn.Dropout(dropout)
# Get the scores (logits)
self.fc = nn.Linear(
in_features=hidden_dim,
out_features=vocab_size,
)
def forward(
self,
# x: (batch_size, seq_length)
x,
):
embedded = self.embedding(x) # (batch_size, seq_length, embedding_dim)
lstm_out, _ = self.lstm(
embedded
) # (batch_size, seq_length, hidden_dim)
# Take only the last output for prediction
last_output = lstm_out[:, -1, :] # (batch_size, hidden_dim)
last_output = self.dropout(last_output)
output = self.fc(last_output) # (batch_size, vocab_size)
return output
Hyperparameters
Model architecture
- Embedding dimension: 128
- Hidden dimension: 512
- No. layers: 2
- Dropout 0.3
Training
For the second training run:
- Learning rate: 0.0005 with a
ReduceLROnPlateauoptimiser - Batch size: 32
- No. epochs: 20
Data
- Sequence length: 10 (the size of the context window)
- Min-token frequency: 2
- Train split: 0.9
Training + Evaluation loop
A fairly standard approach. Cross entropy loss was picked due to being good for multi-class classification, since I’m effectively picking 1 token from a large number of possibilities.
num_epochs = 20
lr = 0.0005
save_dir = "checkpoints"
log_dir = "runs"
criterion = nn.CrossEntropyLoss()
optimiser = optim.Adam(model.parameters(), lr=lr)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimiser,
mode="min",
factor=0.5,
patience=2,
)
# Create directories
Path(save_dir).mkdir(exist_ok=True)
writer = SummaryWriter(log_dir)
print(f"Model parameters: {sum(p.numel() for p in model.parameters()):,}")
best_val_loss = float("inf")
total_batches = len(train_loader) + len(val_loader)
batches_completed = 0
for epoch in range(num_epochs):
epoch_start_time = time.time()
print(f"Epoch {epoch + 1}/{num_epochs}")
print("Training")
# Train
model.train()
train_total_loss = 0
train_correct = 0
train_total = 0
for batch_idx, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
# Forward pass
optimiser.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
# Backward pass
loss.backward()
optimiser.step()
# Statistics
train_total_loss += loss.item()
_, predicted = outputs.max(1)
train_total += targets.size(0)
train_correct += predicted.eq(targets).sum().item()
batches_completed += 1
# Progress with time estimate
if (batch_idx + 1) % 100 == 0:
elapsed = time.time() - epoch_start_time
batches_done_this_epoch = batch_idx + 1
batches_remaining_this_epoch = (
len(train_loader) - batches_done_this_epoch + len(val_loader)
)
epochs_remaining = num_epochs - epoch - 1
# Estimate time remaining this epoch
avg_time_per_batch = elapsed / batches_done_this_epoch
time_remaining_this_epoch = (
avg_time_per_batch * batches_remaining_this_epoch
)
# Estimate time for remaining epochs (rough estimate)
time_per_epoch = elapsed + time_remaining_this_epoch
time_remaining_total = time_remaining_this_epoch + (
time_per_epoch * epochs_remaining
)
print(
f" Batch {batch_idx + 1}/{len(train_loader)} | "
f"Loss: {loss.item():.4f} | "
f"Acc: {100.0 * train_correct / train_total:.2f}% | "
f"ETA: {time_remaining_total / 60:.1f}m"
)
train_avg_loss = train_total_loss / len(train_loader)
train_acc = 100.0 * train_correct / train_total
print("Evaluating")
# Eval
model.eval()
with torch.no_grad():
val_total_loss = 0
val_correct = 0
val_total = 0
for batch_idx, (inputs, targets) in enumerate(val_loader):
inputs, targets = inputs.to(device), targets.to(device)
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, targets)
# Statistics
val_total_loss += loss.item()
_, predicted = outputs.max(1)
val_total += targets.size(0)
val_correct += predicted.eq(targets).sum().item()
# Progress
if (batch_idx + 1) % 100 == 0:
print(
f" Batch {batch_idx + 1}/{len(val_loader)} | "
f"Loss: {loss.item():.4f} | "
f"Acc: {100.0 * val_correct / val_total:.2f}%"
)
val_avg_loss = val_total_loss / len(val_loader)
val_acc = 100.0 * val_correct / val_total
scheduler.step(val_avg_loss)
epoch_time = time.time() - epoch_start_time
# Epoch summary
print(f"\nEpoch {epoch + 1} Summary:")
print(f" Train Loss: {train_avg_loss:.4f} | Train Acc: {train_acc:.2f}%")
print(f" Val Loss: {val_avg_loss:.4f} | Val Acc: {val_acc:.2f}%")
print(f" Time: {epoch_time:.2f}s")
# Tensorboard logging
writer.add_scalar("Loss/train", train_avg_loss, epoch)
writer.add_scalar("Loss/val", val_avg_loss, epoch)
writer.add_scalar("Accuracy/train", train_acc, epoch)
writer.add_scalar("Accuracy/val", val_acc, epoch)
writer.add_scalar("Learning_rate", optimiser.param_groups[0]["lr"], epoch)
# Save best model
if val_avg_loss < best_val_loss:
best_val_loss = val_avg_loss
checkpoint = {
"epoch": epoch,
"model_state_dict": model.state_dict(),
"optimiser_state_dict": optimiser.state_dict(),
"val_loss": val_avg_loss,
"val_acc": val_acc,
"embedding_dim": 128,
"hidden_dim": 512,
"num_layers": 2,
"dropout": 0.3,
}
torch.save(checkpoint, f"{save_dir}/best_model.pt")
print(f" → Saved best model (val_loss: {val_avg_loss:.4f})")
# Save checkpoint every 5 epochs
if (epoch + 1) % 5 == 0:
checkpoint = {
"epoch": epoch,
"model_state_dict": model.state_dict(),
"optimiser_state_dict": optimiser.state_dict(),
"val_loss": val_avg_loss,
"embedding_dim": 128,
"hidden_dim": 512,
"num_layers": 2,
"dropout": 0.3,
}
torch.save(
checkpoint, f"{save_dir}/checkpoint_epoch_{epoch + 1}.pt"
)
print(f"Training complete! Best validation loss: {best_val_loss:.4f}")
vocab_info = {
"vocab": dataset.vocab,
"idx_to_token": dataset.idx_to_token,
"seq_length": seq_length,
}
torch.save(vocab_info, "checkpoints/vocab.pt")
print("Vocabulary saved to checkpoints/vocab.pt")
writer.close()
Sample output:
Epoch 20/20
Training
Batch 100/9760 | Loss: 0.5446 | Acc: 74.84% | ETA: 3.2m
Batch 200/9760 | Loss: 0.9153 | Acc: 75.67% | ETA: 3.3m
Batch 300/9760 | Loss: 0.8639 | Acc: 75.38% | ETA: 3.2m
Batch 400/9760 | Loss: 0.7539 | Acc: 75.51% | ETA: 3.2m
Batch 500/9760 | Loss: 0.4054 | Acc: 75.63% | ETA: 3.2m
Batch 600/9760 | Loss: 0.8173 | Acc: 75.39% | ETA: 3.2m
Batch 700/9760 | Loss: 0.7043 | Acc: 75.33% | ETA: 3.2m
Batch 800/9760 | Loss: 0.9065 | Acc: 75.30% | ETA: 3.1m
Batch 900/9760 | Loss: 1.2786 | Acc: 75.32% | ETA: 3.1m
Batch 1000/9760 | Loss: 0.9698 | Acc: 75.26% | ETA: 3.0m
Batch 1100/9760 | Loss: 0.9276 | Acc: 75.38% | ETA: 3.0m
Batch 1200/9760 | Loss: 0.7024 | Acc: 75.52% | ETA: 3.0m
Batch 1300/9760 | Loss: 1.2020 | Acc: 75.49% | ETA: 2.9m
Batch 1400/9760 | Loss: 1.5876 | Acc: 75.46% | ETA: 2.9m
Batch 1500/9760 | Loss: 1.2633 | Acc: 75.46% | ETA: 2.8m
Batch 1600/9760 | Loss: 0.7142 | Acc: 75.52% | ETA: 2.8m
Batch 1700/9760 | Loss: 0.5224 | Acc: 75.57% | ETA: 2.8m
Batch 1800/9760 | Loss: 0.7682 | Acc: 75.57% | ETA: 2.8m
Batch 1900/9760 | Loss: 0.5953 | Acc: 75.57% | ETA: 2.7m
Batch 2000/9760 | Loss: 0.9208 | Acc: 75.54% | ETA: 2.7m
Batch 2100/9760 | Loss: 0.7212 | Acc: 75.54% | ETA: 2.7m
Batch 2200/9760 | Loss: 0.5170 | Acc: 75.50% | ETA: 2.7m
Batch 2300/9760 | Loss: 1.3677 | Acc: 75.52% | ETA: 2.6m
Batch 2400/9760 | Loss: 1.1310 | Acc: 75.60% | ETA: 2.6m
Batch 2500/9760 | Loss: 1.0251 | Acc: 75.65% | ETA: 2.6m
Batch 2600/9760 | Loss: 1.0081 | Acc: 75.65% | ETA: 2.5m
Batch 2700/9760 | Loss: 0.6257 | Acc: 75.71% | ETA: 2.5m
Batch 2800/9760 | Loss: 0.6302 | Acc: 75.76% | ETA: 2.5m
Batch 2900/9760 | Loss: 1.1084 | Acc: 75.73% | ETA: 2.4m
Batch 3000/9760 | Loss: 0.9276 | Acc: 75.74% | ETA: 2.4m
Batch 3100/9760 | Loss: 1.0514 | Acc: 75.76% | ETA: 2.4m
Batch 3200/9760 | Loss: 1.0324 | Acc: 75.73% | ETA: 2.3m
Batch 3300/9760 | Loss: 0.9521 | Acc: 75.75% | ETA: 2.3m
Batch 3400/9760 | Loss: 0.9311 | Acc: 75.75% | ETA: 2.3m
Batch 3500/9760 | Loss: 1.3574 | Acc: 75.71% | ETA: 2.2m
Batch 3600/9760 | Loss: 1.3204 | Acc: 75.70% | ETA: 2.2m
Batch 3700/9760 | Loss: 0.8205 | Acc: 75.65% | ETA: 2.2m
Batch 3800/9760 | Loss: 0.8480 | Acc: 75.65% | ETA: 2.1m
Batch 3900/9760 | Loss: 1.0053 | Acc: 75.63% | ETA: 2.1m
Batch 4000/9760 | Loss: 0.8431 | Acc: 75.62% | ETA: 2.1m
Batch 4100/9760 | Loss: 0.6486 | Acc: 75.63% | ETA: 2.0m
Batch 4200/9760 | Loss: 1.1627 | Acc: 75.61% | ETA: 2.0m
Batch 4300/9760 | Loss: 0.8758 | Acc: 75.60% | ETA: 2.0m
Batch 4400/9760 | Loss: 0.6203 | Acc: 75.57% | ETA: 2.0m
Batch 4500/9760 | Loss: 1.1223 | Acc: 75.55% | ETA: 1.9m
Batch 4600/9760 | Loss: 0.7320 | Acc: 75.56% | ETA: 1.9m
Batch 4700/9760 | Loss: 0.9346 | Acc: 75.56% | ETA: 1.9m
Batch 4800/9760 | Loss: 1.3005 | Acc: 75.54% | ETA: 1.8m
Batch 4900/9760 | Loss: 0.7396 | Acc: 75.54% | ETA: 1.8m
Batch 5000/9760 | Loss: 1.5404 | Acc: 75.52% | ETA: 1.8m
Batch 5100/9760 | Loss: 0.8719 | Acc: 75.51% | ETA: 1.7m
Batch 5200/9760 | Loss: 0.7972 | Acc: 75.50% | ETA: 1.7m
Batch 5300/9760 | Loss: 0.6451 | Acc: 75.47% | ETA: 1.7m
Batch 5400/9760 | Loss: 0.8698 | Acc: 75.44% | ETA: 1.7m
Batch 5500/9760 | Loss: 1.1309 | Acc: 75.43% | ETA: 1.6m
Batch 5600/9760 | Loss: 1.3389 | Acc: 75.46% | ETA: 1.6m
Batch 5700/9760 | Loss: 1.5162 | Acc: 75.46% | ETA: 1.6m
Batch 5800/9760 | Loss: 0.8265 | Acc: 75.47% | ETA: 1.5m
Batch 5900/9760 | Loss: 1.0054 | Acc: 75.47% | ETA: 1.5m
Batch 6000/9760 | Loss: 0.6175 | Acc: 75.46% | ETA: 1.5m
Batch 6100/9760 | Loss: 1.0839 | Acc: 75.47% | ETA: 1.4m
Batch 6200/9760 | Loss: 0.6915 | Acc: 75.48% | ETA: 1.4m
Batch 6300/9760 | Loss: 1.3891 | Acc: 75.51% | ETA: 1.4m
Batch 6400/9760 | Loss: 0.7335 | Acc: 75.51% | ETA: 1.4m
Batch 6500/9760 | Loss: 0.6722 | Acc: 75.51% | ETA: 1.3m
Batch 6600/9760 | Loss: 0.9038 | Acc: 75.50% | ETA: 1.3m
Batch 6700/9760 | Loss: 1.3391 | Acc: 75.51% | ETA: 1.3m
Batch 6800/9760 | Loss: 0.7128 | Acc: 75.51% | ETA: 1.2m
Batch 6900/9760 | Loss: 0.5310 | Acc: 75.50% | ETA: 1.2m
Batch 7000/9760 | Loss: 0.4042 | Acc: 75.49% | ETA: 1.2m
Batch 7100/9760 | Loss: 1.5237 | Acc: 75.48% | ETA: 1.1m
Batch 7200/9760 | Loss: 1.0661 | Acc: 75.48% | ETA: 1.1m
Batch 7300/9760 | Loss: 0.9559 | Acc: 75.47% | ETA: 1.1m
Batch 7400/9760 | Loss: 1.3439 | Acc: 75.49% | ETA: 1.1m
Batch 7500/9760 | Loss: 1.3181 | Acc: 75.50% | ETA: 1.0m
Batch 7600/9760 | Loss: 1.2349 | Acc: 75.51% | ETA: 1.0m
Batch 7700/9760 | Loss: 0.8291 | Acc: 75.52% | ETA: 1.0m
Batch 7800/9760 | Loss: 1.0304 | Acc: 75.51% | ETA: 0.9m
Batch 7900/9760 | Loss: 1.1334 | Acc: 75.49% | ETA: 0.9m
Batch 8000/9760 | Loss: 0.8924 | Acc: 75.50% | ETA: 0.9m
Batch 8100/9760 | Loss: 0.8017 | Acc: 75.50% | ETA: 0.8m
Batch 8200/9760 | Loss: 0.9542 | Acc: 75.51% | ETA: 0.8m
Batch 8300/9760 | Loss: 0.7942 | Acc: 75.51% | ETA: 0.8m
Batch 8400/9760 | Loss: 1.0252 | Acc: 75.52% | ETA: 0.7m
Batch 8500/9760 | Loss: 0.9583 | Acc: 75.52% | ETA: 0.7m
Batch 8600/9760 | Loss: 1.1893 | Acc: 75.54% | ETA: 0.7m
Batch 8700/9760 | Loss: 0.3795 | Acc: 75.56% | ETA: 0.7m
Batch 8800/9760 | Loss: 0.3930 | Acc: 75.57% | ETA: 0.6m
Batch 8900/9760 | Loss: 0.3281 | Acc: 75.58% | ETA: 0.6m
Batch 9000/9760 | Loss: 0.6453 | Acc: 75.57% | ETA: 0.6m
Batch 9100/9760 | Loss: 0.6037 | Acc: 75.57% | ETA: 0.5m
Batch 9200/9760 | Loss: 0.4937 | Acc: 75.59% | ETA: 0.5m
Batch 9300/9760 | Loss: 0.6606 | Acc: 75.59% | ETA: 0.5m
Batch 9400/9760 | Loss: 1.1933 | Acc: 75.60% | ETA: 0.4m
Batch 9500/9760 | Loss: 0.7279 | Acc: 75.59% | ETA: 0.4m
Batch 9600/9760 | Loss: 0.8939 | Acc: 75.59% | ETA: 0.4m
Batch 9700/9760 | Loss: 0.5908 | Acc: 75.59% | ETA: 0.4m
Evaluating
Batch 100/1085 | Loss: 3.1492 | Acc: 64.59%
Batch 200/1085 | Loss: 1.1238 | Acc: 66.00%
Batch 300/1085 | Loss: 2.0473 | Acc: 66.01%
Batch 400/1085 | Loss: 3.0740 | Acc: 66.55%
Batch 500/1085 | Loss: 2.0922 | Acc: 66.58%
Batch 600/1085 | Loss: 4.7091 | Acc: 66.22%
Batch 700/1085 | Loss: 1.9975 | Acc: 66.30%
Batch 800/1085 | Loss: 2.6130 | Acc: 66.34%
Batch 900/1085 | Loss: 2.1577 | Acc: 66.21%
Batch 1000/1085 | Loss: 2.0467 | Acc: 66.11%
Epoch 20 Summary:
Train Loss: 0.9653 | Train Acc: 75.58%
Val Loss: 2.0829 | Val Acc: 66.14%
Time: 189.36s
Training complete! Best validation loss: 2.003
Metrics
I mentioned the second training run, since these results have about 15% better accuracy, after increasing the hidden dimensions from 256 → 512 and no. of epochs from 10 → 20. Possibly unsurprising, the training runtime doubled.
Accuracy
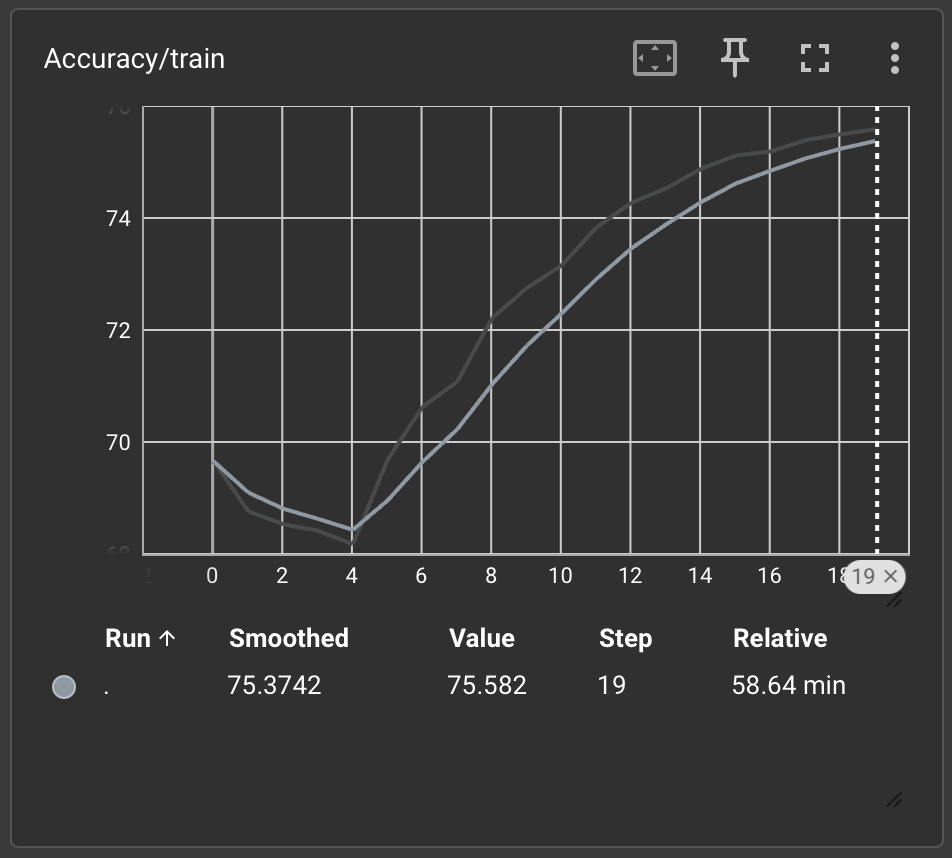
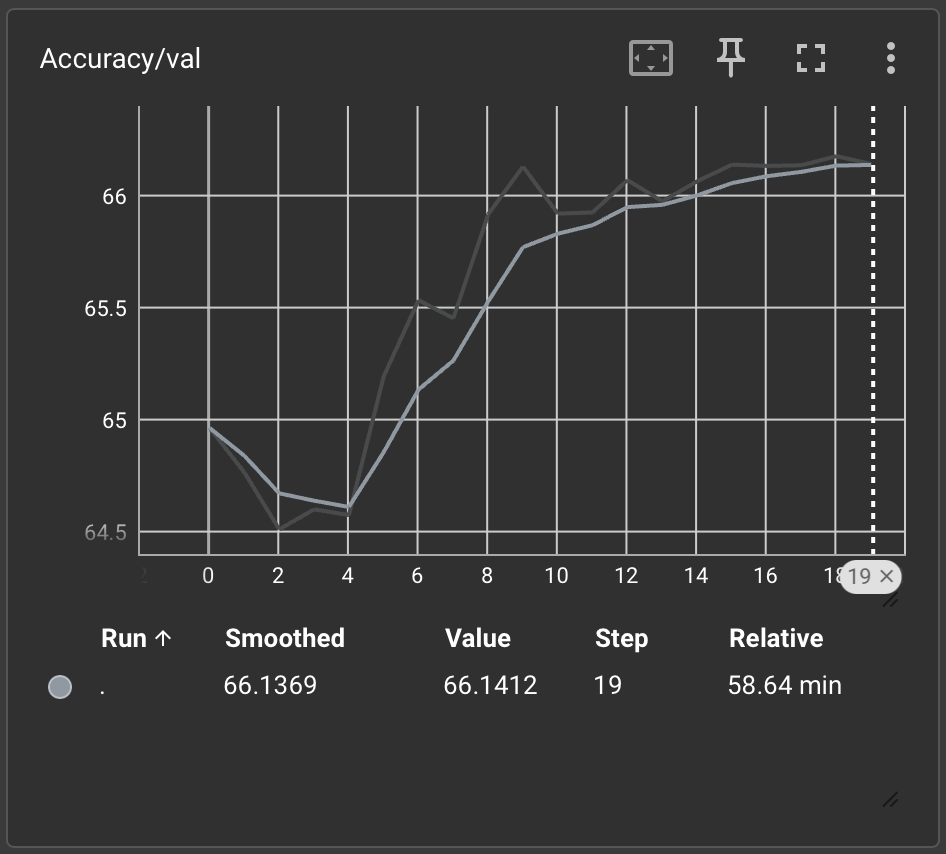
Loss
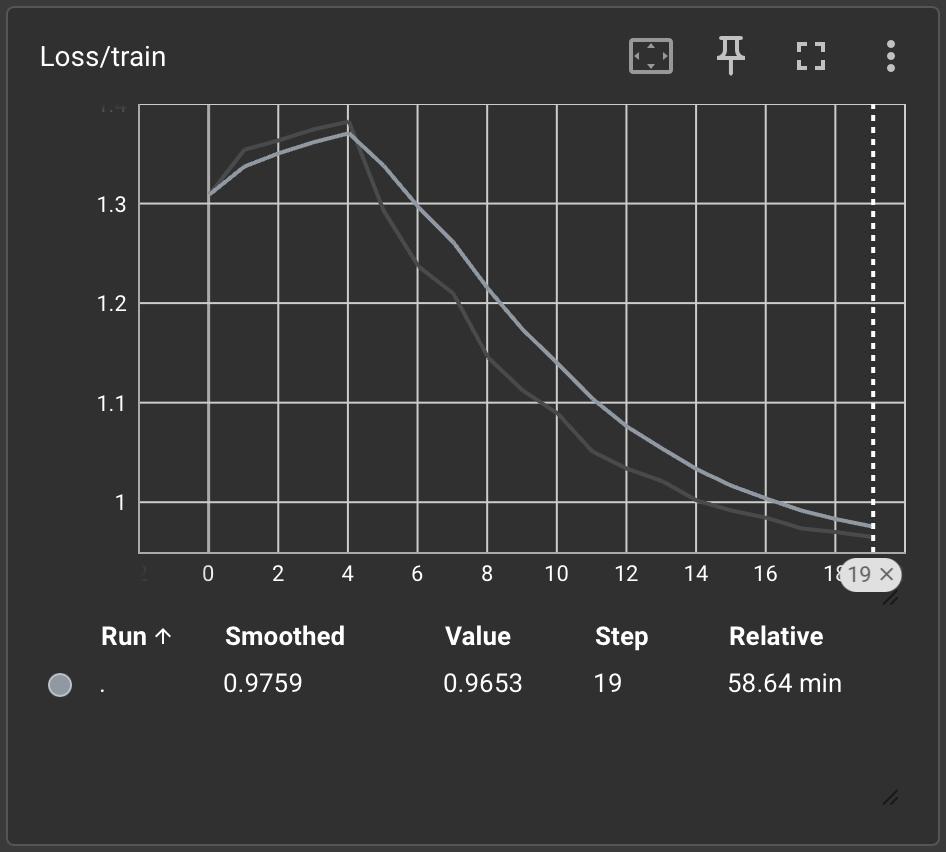
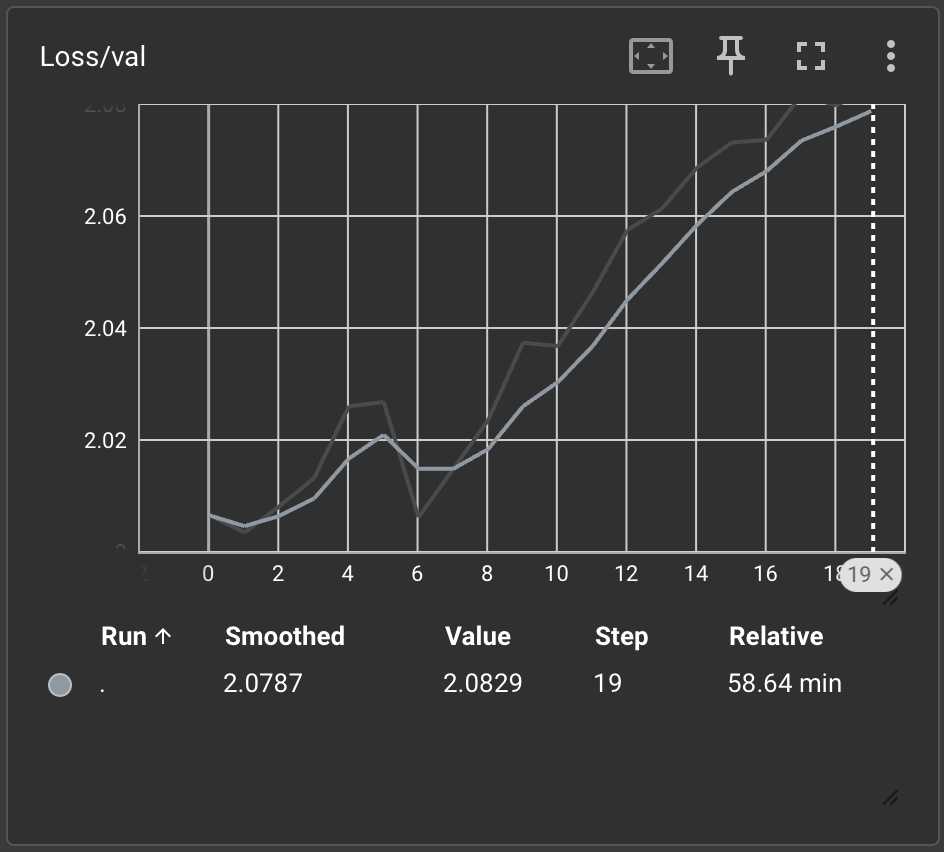
Learning rate
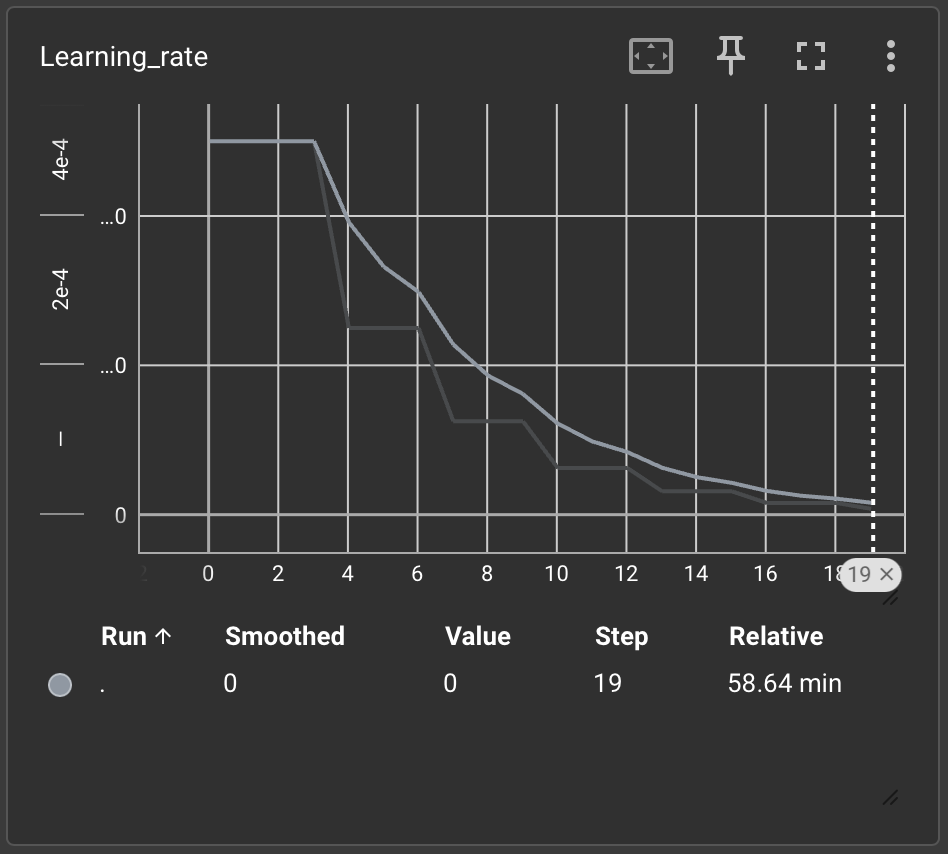
Predictions
A quick script:
def tokenize_command(command):
tokens = re.findall(r"\S+", command)
refined_tokens = []
for token in tokens:
parts = re.split(r"([|&;<>(){}[\]])", token)
refined_tokens.extend([p for p in parts if p])
refined_tokens.append("<EOS>")
return refined_tokens
def predict(command, top_k=5):
tokens = tokenize_command(command)
indices = [vocab_loaded.get(t, vocab_loaded["<UNK>"]) for t in tokens][
-seq_length_loaded:
]
print(f"{indices=}")
# No padding for short sequences
indices_tensor = torch.tensor([indices])
print(f"{indices_tensor=}")
with torch.no_grad():
output = model_loaded(indices_tensor)
print(f"{output=}")
print(f"{output[0].shape=}")
probs = torch.softmax(output[0], dim=0)
print(f"{probs=}")
top_probs, top_idx = torch.topk(probs, top_k)
print(f"{top_probs=}, {top_idx=}")
for prob, idx in zip(top_probs, top_idx):
print(f"{idx_to_token_loaded[idx.item()]}: {prob.item() * 100:.1f}%")
predict("git")
predict("git commit -m")
predict("brew list")
predict("nvim")
git: 42.8%
g: 6.9%
<UNK>: 4.0%
nvim: 3.8%
rg: 3.8%
<UNK>: 28.1%
git: 27.7%
g: 3.7%
vespa: 2.5%
from: 2.2%
brew: 70.1%
mise: 4.3%
c: 2.8%
cd: 2.4%
zx: 2.1%
nvim: 24.9%
cd: 5.8%
c: 5.8%
rm: 4.1%
poetry: 3.6%
Data
I use Fish and Atuin1. I have shell history going back more than 5 years! From ZSH → Fish → Fish with Atuin.
Exporting Atuin history
I used a simple script, to export to JSONL.
import json
import sqlite3
from pathlib import Path
def main() -> None:
"""Export Atuin history to JSONL file."""
home = Path.home()
db_path = home / ".local/share/atuin/history.db"
output_file = Path("data/atuin_history.jsonl")
# Connect to Atuin database
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# Query history ordered by timestamp
cursor.execute(
"SELECT id, timestamp, duration, exit, command, cwd, session, hostname "
"FROM history ORDER BY timestamp ASC"
)
# Write to JSONL file
with open(output_file, "w") as f:
for row in cursor:
record = {
"id": row[0],
"timestamp": row[1] // 1_000_000_000, # Convert nanoseconds to seconds
"duration_ms": row[2],
"exit_code": row[3],
"command": row[4],
"cwd": row[5],
"session": row[6],
"hostname": row[7],
}
f.write(json.dumps(record) + "\n")
conn.close()
print(f"Exported to {output_file}")
if __name__ == "__main__":
main()
Loading data
Used a standard Torch DataLoader.
seq_length = 10
min_freq = 2
batch_size = 32
train_split = 0.9
num_workers = 0
jsonl_path = "data/atuin_history.jsonl"
dataset = ShellCommandDataset(jsonl_path, seq_length, min_freq)
# Split into train and validation
train_size = int(train_split * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(
dataset,
[train_size, val_size],
generator=torch.Generator().manual_seed(42), # For reproducibility
)
# Create dataloaders
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
pin_memory=torch.cuda.is_available(),
)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=num_workers,
pin_memory=torch.cuda.is_available(),
)