We can't find the internet
Attempting to reconnect
Something went wrong!
Hang in there while we get back on track
Explicitly showing, and checking, documentation decay
2024-09-14 ・ documentation, readme
The problem with manual links
Have you ever seen perfectly up-to-date documentation? What about a SaaS product's API documentation? For the latter, there's well known approaches, and tools, for documentation generation. I've seen a kind of new tools that will monitor your requests/responses, to catch drift. I'll focus on the former for now.
On 2023-08-22, I was looking at Elastic's Helm charts, and found a link to an external page that had been archived, and that's when I had the first idea of "documentation decay". On 2023-12-30, I wrote about how I've heard previous colleagues talk about how important it is to have documentation "next to" code, to supposedly increase the likelihood that it's kept recent. I don't disagree, but that's just 1 "link".
At a recent job, I noticed that the link checker for the documentation wasn't automatically being run. I ran it and found over 100 broken links, which included links to other pages in the documentation, and to external websites.
That is just one kind of link. Another kind of link could be something like the supported versions of Kubernetes. I setup a variable for that, so that that variable was used everywhere in the documentation. This meant that it was always up-to-date. That isn't true of course, since the version of Kubernetes that was supported had its source-of-truth elsewhere. There was a link to be manually updated.
Anything that is manual will eventually be forgotten, or remembered, but done incorrectly. One day I'll write about my checklist idea.
Code, or rather documentation, generation helps
Adding the variable, and then the documentation generation did its bit. There's 3 fundamental things about it that I'll go into.
- Displaying state
- Static checks
- Linking anything
What are links?
There's anchors, in the web sense. Then there's anything else! "Container" kinds of things are full of them, like READMEs and Makefiles. There is some fanciful idea of everything being a computation graph deep down.
1. Displaying state
Assume that there are links for anything. Notion, a common choice, has a way to mark things as verified1 and to sync blocks2. What if there was more? In the mockup below, I've used visual markings to indicate the state of decay, and to include the reasons for the decay:
NB: You can open the image in a new tab, to see it in a larger size.
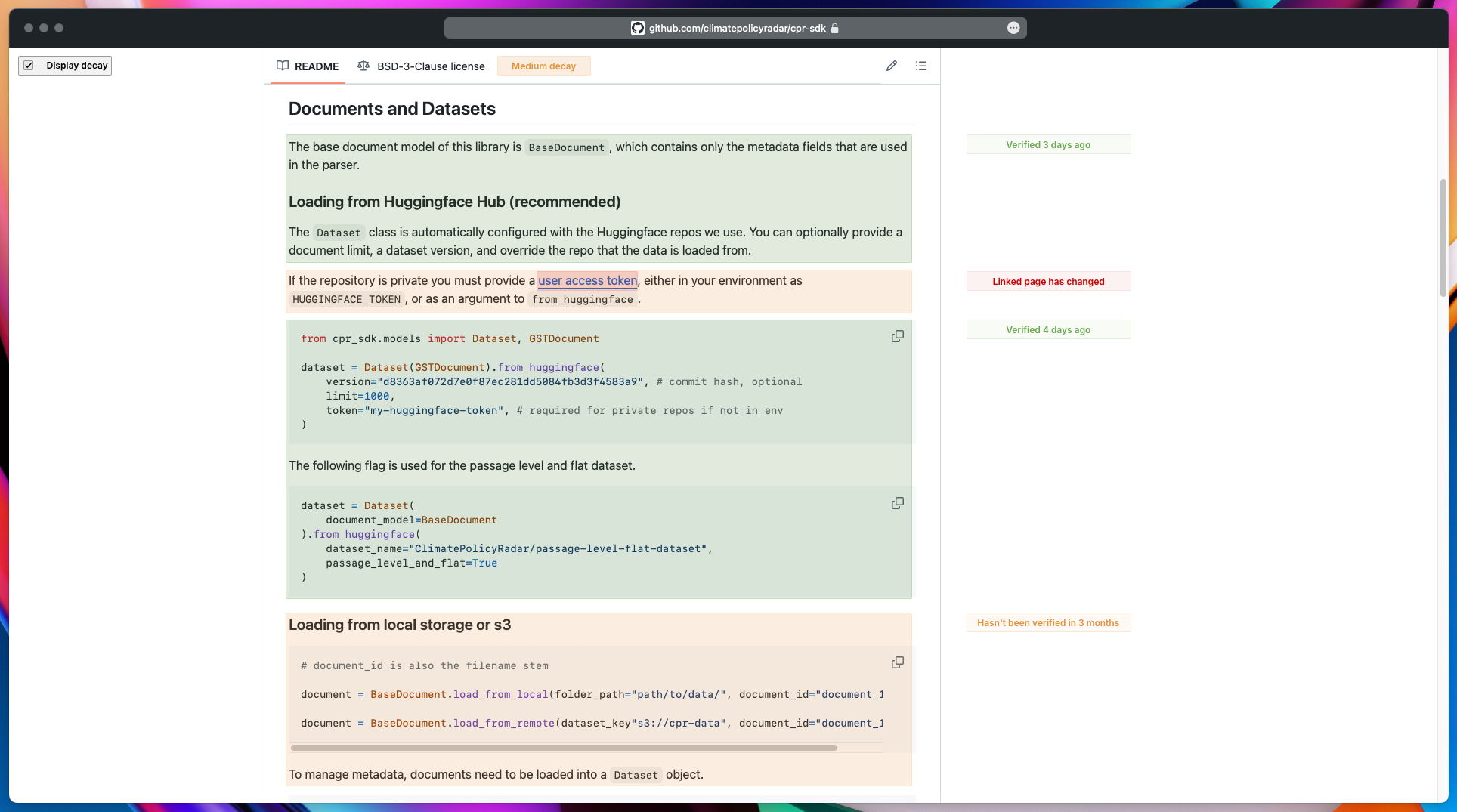
What would this do? It can help you set off in the right way, with an appropriate amount of trust and expectations.
2. Static checks
For a recent side-project3, I'm using Justfiles for making the different tasks manageable. You can see where I changed the Justfile4 to account for the other, meaningful changes. At first I had missed this. What if I had a static check to remind me?
I wrote up a small script that would check the links, with the Justfile (A) having links to the folder existing (B), and the configuration of the output directory (C).
import json
import os
import tomllib
from difflib import unified_diff
def a_accessor():
with open("justfile", "r") as file:
lines = file.readlines()
if len(lines) >= 2:
second_line = lines[1]
extracted_content = second_line[4:64]
return extracted_content.strip()
def b_accessor():
return os.path.exists("data/02-plaintext-to-vespa-documents")
def c_accessor():
with open("data/02-plaintext-to-vespa-documents/config.toml", "rb") as f:
config = tomllib.load(f)
return config["data"]["output_file"]
def get_state(value=None):
state_file = "state.json"
with open(state_file, "r") as f:
return json.load(f)
if __name__ == "__main__":
expected = get_state()
actual = {
"a": {"value": a_accessor()},
"b": {"value": b_accessor()},
"c": {"value": c_accessor()},
}
actual_str = json.dumps(actual, indent=2)
expected_str = json.dumps(expected, indent=2)
diff = list(
unified_diff(
actual_str.splitlines(keepends=True),
expected_str.splitlines(keepends=True),
fromfile="actual",
tofile="expected",
lineterm="",
)
)
if diff:
print("Differences found:")
print("".join(diff))
with open("links.json", "r") as f:
links = json.load(f)
print(json.dumps(links, indent=2))
print("\nPlease check the links above.")
exit(1)
else:
print("No differences found.")
exit(0)
Here is the state:
{
"a": {
"value": "data/02-plaintext-to-vespa-documents/output/vespa-all.jsonl"
},
"b": {
"value": true
},
"c": {
"value": "output/vespa-all.jsonl"
}
}
Here are the links:
{
"a": {
"links": ["b", "c"]
},
"b": {
"links": ["a", "c"]
},
"c": {
"links": ["a", "b"]
}
}
A forced negative output:
$ poetry run python clevis.py
Differences found:
--- actual+++ expected@@ -6,6 +6,6 @@ "value": true
},
"c": {
- "value": "output/vespa-all.jsonl"
+ "value": "output/vespa.jsonl"
}
}
{
"a": {
"links": [
"b",
"c"
]
},
"b": {
"links": [
"a",
"c"
]
},
"c": {
"links": [
"a",
"b"
]
}
}
Please check the links above.
As a once off, this is okay, but is not realistic for even a small side-project like that, let alone for a professional environment. Like with all documentation, tooling, CI/CD, tests, etc., the convenience matters. No tools currently exist for this convenience, so they would need to be created.
This part is simpler, in the sense that it would need to load the previous state, create the new state, and compare them for differences.
3. Linking anything
Similar to the point above, there needs to be tooling for creating links! What is anything? A README is a simple example. Anything that has programmatic access could have tooling made for. It could be a public landing page to an internal Notion page, or cross-repository.
Conclusion
I'll intentionally document examples of where this comes up at my job and in side-projects, and think about what that tooling would look like.
I've noticed more happening in the world of non-string treatment of code, whether that's from Tree-sitter (and LSP), to Codemod, Grit, Semgrep, Ki Editor, and much more. This is a trend I'm very happy to see! One thing that I didn't touch on is fixing. Pointing out mistakes doesn't mean they'll even get fixed. Automated fixing, like with formatters and static checks, increases the likelihood of them being made.